Der Import von PDF-Dateien, d.h. das Transferieren von Inhalt aus PDF-Dateien in einen Artikel (Textformat) ist technisch gesehen eine Herausforderung, und aufgrund der vielfältigen Ausgangssituationen gelingt nicht jeder Import in gewünschter Weise.
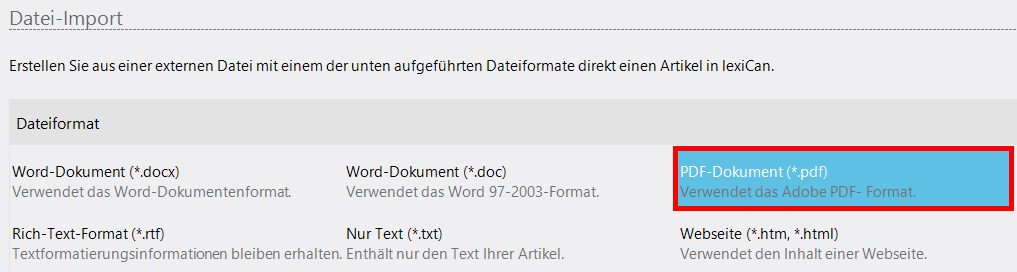
Nachfolgend soll auf die Besonderheiten des Imports von PDF-Dateien näher eingegangen werden.
PDF ist ein Format zur Beschreibung von Dokumentenseiten. Sein originärer Zweck war es, Dokumente unter weitestgehendem Erhalt des Layouts und der Formatierung auf verschiedenen Betriebssystemplattformen anzuzeigen. Das komplette Zurückführen von Inhalten aus PDF-Dateien in eine Textform war nie vorgesehen.
Eine PDF-Datei beinhaltet detaillierte Informationen über die Erscheinung von Schriftzeichen, aber nicht notwendigerweise auch über ihre Bedeutung. D.h. es ist genau festgelegt, wie ein Schriftzeichen auszusehen hat und an welcher Position im Schriftstück es sich befindet. Es findet sich jedoch keine Information über die Normierung des Schriftzeichens. Aus diesem Grund ist der Import von Text aus PDF-Dateien in vielen Fällen nur eingeschränkt möglich.
Neben dem Fehlen von Informationen zur Normierung fehlen jegliche Hinweise zur Ordnung und zum Textfluss sowie darüber, ob ein Textbestandteil eine Überschrift darstellt oder sich in einer Tabelle befindet. Obwohl kürzliche Verbesserungen in der Spezifikation des PDF-Formats es zulassen, sind solche Informationen nur selten in PDF-Dokumenten beinhaltet. Glücklicherweise enthält die Mehrheit der PDF-Dokumente die ein oder andere Form von Schriftzeichenzuordnung, die es einem PDF-Reader ermöglicht, Text in eine Unicode-Zeichenkette umzusetzen.
Bei Auswahl von "Nur Text" unter "PDF-Import-Optionen" lexiCan extrahiert und transferiert alle Textbestandteile, die es findet, ergänzt fehlende Leerzeichen und Zeilenumbrüche und sortiert Textblöcke so, dass sie in ihrer logischen Reihenfolge erscheinen. Der resultierende Text besteht dann aus einzelnen Textzeilen mit einem Zeilenumbruch am Ende jeder Zeile.
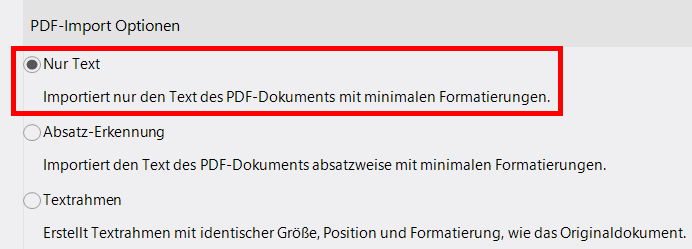
Beim Import mit Hilfe der "Absatz-Erkennung" kann lexiCan diese einzelnen Textzeilen zu größeren Textblöcken kombinieren, was das Editieren des Textes angenehmer macht.
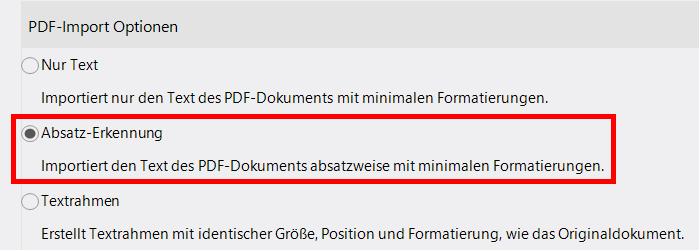
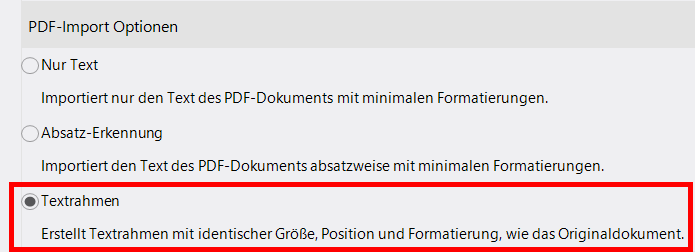
Die dritte Option ermöglicht es, Text in Rahmen abzubilden. Dadurch können das ursprüngliche Layout des PDF-Dokuments erhalten und – nicht ganz unwichtig – Bildbestandteile berücksichtigt werden.
Siehe auch Artikel mittels Dateiimport erstellen